Análisis de los accesos no-humanos (eliminando lectores y usuarios) a un artículo web durante sus primeras 24 horas de vida.
¡Ojo! Hago directos en Twitch sobre desarrollo web, ¿Te apuntas? ManzDev 
Robots: Accesos no humanos a la web
Escrito por J. Román Hernández Martín
Por lo general, estamos acostumbrados a pensar que todo acceso o visita registrada en una página web es un visitante o lector interesado en lo que allí se publicó. Sin embargo, muchos de estos accesos son realizados por un sistema automático y se denominan robots, crawlers o bots.
Los robots o bots son la forma más genérica de estos sistemas automatizados. Por otro lado, los crawlers (también llamados spiders) son unos bots más específicos, encargados de recopilar información para procesar e incorporarla posteriormente a un sistema concreto, como por ejemplo, un buscador web.

En este análisis he realizado un seguimiento de los accesos recibidos a un artículo concreto durante sus primeras 24 horas de vida. He eliminado todos los accesos de lectores reales, mostrando sólo los pertenecientes a robots.
Para identificar el acceso de los diferentes robots se examina el llamado User Agent, un campo de texto que envía obligatoriamente el sistema que realiza el acceso.
Sin embargo, este texto es fácilmente falsificable, por lo que se recomienda examinar también el rango de IP (y su DNS inverso) para comprobar si es realmente quien dice ser. Muchos spam bots se hacen pasar por robots legítimos con el objetivo de recopilar emails o enviar spam.
La mayoría de estos robots siguen un código de buenas conductas definido en el robots.txt. Por aquí tienes una guía detallada sobre robots.txt. Sin embargo, sólo son recomendaciones, lee esto si quieres bloquear accesos por la fuerza.
Es importante remarcar que este análisis no intenta ser un caso representativo universal. Simplemente es útil para hacernos una idea y saber datos como la velocidad de algunos robots o crawlers, la variedad existente o lo activos que son en los primeros momentos de vida de un artículo.
Para mayor claridad visual, he dividido los accesos en 3 gráficas diferentes: los primeros 5 minutos, los primeros 60 minutos y las primeras 24 horas. Además, he omitido los bots que repetían accesos.
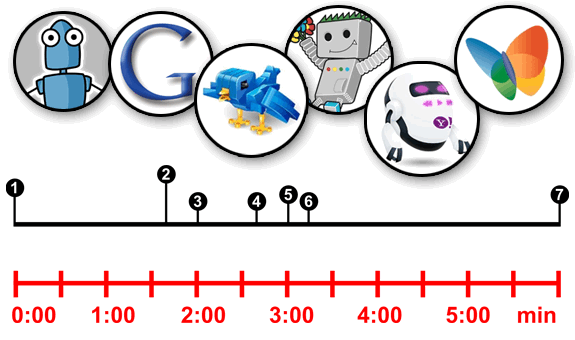
Gráfica 1: Accesos durante los primeros 5 minutos de la publicación del artículo.
Kcy / MediaPartners
Nada más publicar el artículo, en el primer segundo, ya recibimos dos accesos de dos bots. Por una parte, Kcy, que es el crawler de Karmacracy, que se encarga de acortar las URL de este blog. Nos visita desde su subdominio nono.
El otro crawler, es Mediapartners-Google, el mismísimo robot de Google Adsense, encargado de examinar el artículo para enviar anuncios relacionados con el contenido de la página.
Googlebot / Yahoo Slurp / Twitterbot
Poco antes de cumplirse los dos minutos, acceden varios pesos pesados. El primero de ellos es Googlebot, crawler hermano del anterior (accede desde la misma IP) que se encarga de indexar el contenido de un artículo para mostrarlo en el buscador.
Tras el, llega Twitterbot, un bot oficial de Twitter que se ha puesto en funcionamiento probablemente tras la publicación de un tweet con un enlace hacia el artículo. Proviene del subdominio spiderduck.
El tercer crawler en cuestión es Yahoo! Slurp, el robot de indexación del buscador de Yahoo!. Que por cierto, la genial imagen del robot de Yahoo! es obra de Anekdamian.
Además, acceden algunos otros bots como InAGist o JS-Kit resolver, y un poco más tarde Suggybot.
Butterfly / Bitlybot / MSNBot
Alrededor de los 3 minutos, varios robots como Butterfly, el crawler del buscador social a tiempo real Topsy, Bitlybot, robot acortador de Bit.ly u otros menos conocidos que utilizan el módulo AnyEvent o un misterioso y desconocido BiruBot.
Finalmente, cerca de los 6 minutos, nos encontramos con un caso curioso. Dos accesos de los crawlers MSNBot, correspondiente al buscador MSN de Microsoft, que posteriormente se convirtió en Live y más tarde en Bing.
Ni siquiera el enlace que nos provee la identificación del User Agent funciona, sin embargo, supongo que la información recolectada la utilizarán para el buscador Bing (ver más adelante). El primer crawler corresponde a msnbot, mientras que el segundo a msnbot-NewsBlogs.
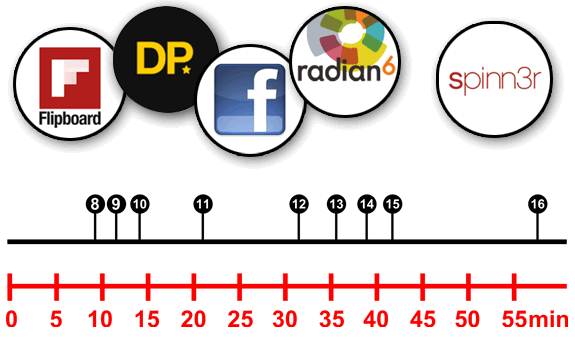
Gráfica 2: Accesos durante los primeros 60 minutos de la publicación del artículo.
TweetMeme / FlipboardProxy / FacebookExternalHit
Entre los primeros 10 y 15 minutos, nos encontramos el acceso de varios robots. El primero de ellos, TweetmemeBot, un buscador de tendencias de Twitter, llamado TweetMeme. Nos visita desde el subdominio ravenpub.
Más adelante, visitarían dos crawlers más. Por un lado, FlipboardProxy, un robot que se encarga de procesar la información obtenida para mostrarla de forma más amigable en otros entornos, por ejemplo, tablets.
Poco después llegaría el bot FacebookExternalHit, un bot de Facebook que se encarga de visitar una página web compartida en Facebook por algún usuario, y realizar una recopilación de varios datos: descripción, título y una imagen de previsualización.
Summify / DailyPerfect / Spinn3r
A los 20 minutos, aproximadamente, nos llega Summify, el crawler de un servicio que se encarga de crear un sumario de varios artículos a modo de resumen, algo muy utilizado en Twitter.
Antes de llegar a los 45 minutos, nos visitan varios bots más, entre los que destaco radian6, DailyPerfect o Printful, todos servicios de monitorización de información capturada de redes sociales o reformateo para otras plataformas. Este último nos visita desde el subdominio hades.
Rozando la hora de vida del artículo, recibimos la visita de Spinn3r, un crawler de información para buscadores y estadísticas y TweetedTimesBot, otro generador de sumarios personalizados.
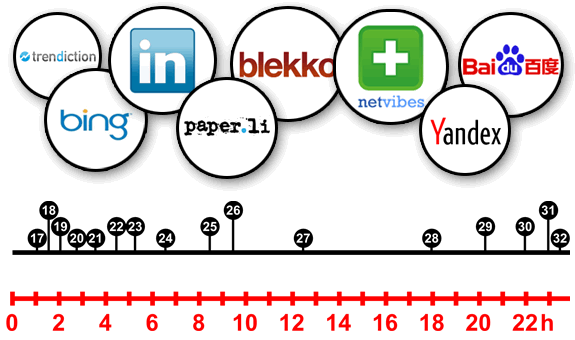
Gráfica 3: Accesos durante las primeras 24 horas de la publicación del artículo.
Una vez pasamos la primera hora de vida del artículo, podemos observar que el acceso de robots no es tan frecuente y se encuentra más disperso.
Durante las dos primeras horas, recibimos de visita a bots variados, entre los que destacamos PaperLiBot (otro generador de sumarios), ProxiMic, TrendictionBot u OutBrain.
LinkedInBot / YandexBot
Antes de llegar a las primeras 5 horas, también accede el crawler LinkedInBot, encargado de revisar enlaces dirigidos desde la famosa red social de trabajo.
Tampoco falta el acceso de YandexBot, el crawler del buscador más utilizado en Rusia, por encima de Google (65% frente a 25%). Más robots variados acceden posteriormente, como Magpie-Crawler, StrawberryJ.am o MetaURI.
Baidu / NetVibes / BingBot
Cerca de las 9 horas, el robot BaiduSpider, perteneciente al buscador chino Baidu, hace aparición, junto al crawler del famoso escritorio online NetVibes.
Rozando las 10 horas desde la publicación del artículo, hace aparición BingBot, ahora sí, el crawler del buscador actual de Microsoft, Bing.
Continuan accediendo más bots como el robot de Worio, el de Trunk.ly o ScoutJet, crawler de Blekko, entre muchos otros.
ia_archive
Finalmente, terminamos el informe mencionando la llegada, casi a las 24 horas de la publicación inicial, de ia_archiver, el crawler de Alexa, utilizado también por la famosa Wayback Machine.
En Emezeta publicamos una vez El paso del tiempo en 20 sitios webs, un artículo con 20 páginas webs famosas y como eran en sus inicios.
Es importante recalcar, que aunque en el pasado su UserAgent fue ia_archiver, en la actualidad es ia_archiver(OS-Wayback), y conviene comprobar que su rango IP pertenece a 207.241.224.0 - 207.241.239.255, ya que es un bot muy propenso a ser falsificado por bots de spam.
